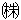 ) Restricted Characters
) Restricted CharactersThis section of the Readme contains known data retrieval (Universal Data Access) issues that apply to several components of the solution.
When running queries that return large result sets, unexpectedly large amounts of memory are consumed on UNIX systems when using certain versions of the Oracle 9iR2 client software. For example, when returning 5,000 or more rows using Oracle 9iR2 client software that is earlier than version 9.2.0.5, some reports may take 150% to 500% of the memory typically used by later versions of this client or the Oracle 8i software.
To resolve this problem, we recommend that you use version 9.2.0.5 or higher versions of the Oracle UNIX database client software.
IBM Cognos Series 7 includes several mechanisms that manage the Japanese vendor-defined characters (VDC) that were assigned with multiple code points in the Shift-JIS encoding standard. These characters are allocated in the following code ranges:
Characters and symbols that are assigned with multiple code points are treated as restricted characters. A support mechanism exists for the following restricted characters.
IBM - 0xFA5C – 0xFC4B are the supported code points for these multiple code points:
For the following multiple code points, IBM - 0xFA40 - 0xFA49 are the supported code points:
For the following multiple code points, NEC - 0x8754 - 0x875D are the supported code points:
) Restricted CharactersFor any multiple code point combination, 0x878A is the supported code point.
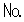 Sign Restricted Character
Sign Restricted CharacterFor any multiple code point combination, 0x8782 is the supported code point.
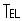 Sign Restricted Character
Sign Restricted CharacterFor any multiple code point combination, 0x8784 is the supported code point.
 Not Sign Restricted Character
Not Sign Restricted CharacterFor any multiple code point combination, 0x81CA is the supported code point.
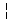 Broken Bar Restricted Character
Broken Bar Restricted CharacterFor any multiple code point combination, 0xFA55 is the supported code point.
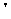 Apostrophe Restricted Character
Apostrophe Restricted CharacterFor any multiple code point combination, 0xFA56 is the supported code point.
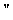 Quotation Mark Restricted Character
Quotation Mark Restricted CharacterFor any multiple code point combination, 0xFA57 is the supported code point.
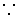 Restricted Character
Restricted CharacterFor any multiple code point combination, 0x81E6 is the supported code point.
For the following multiple code points, regular symbol - 0x8140 - 0x81FC is the supported code point:
All VDC characters and symbols that are assigned with a single code point are treated as non-restricted characters and they are supported as other Japanese characters.
IBM Cognos Series 7 doesn’t supply a mechanism to detect or warn users when non-supported code points are entered.
In addition to the Japanese Shift-JIS encoding, IBM Cognos NoticeCast supports EUC-JP and ISO-2022-JP encoding for outgoing email. This feature will allow the customer to read alerts and notifications sent by email systems that require these encodings. However, Japanese VDC code ranges, especially restricted characters, are not fully supported by JAVA runtime. When IBM Cognos NoticeCast is configured to use EUC-JP or ISO-2022-JP as the encoding for outgoing email, using the VDC characters in email body and subject are not supported.